Aujourd’hui, nous allons parler de veille concurrentielle. Nous avons développé un outil pour être informés des évolutions du catalogue de produits (en l’occurrence, des formations) de nos concurrents. La méthode utilisé n’étant pas spécifique à notre marché et comme nous nous sommes bien amusés à coder tout ça, nous avons décidé de vous en parler :)
Disclaimer : Nous sommes toujours très respectueux de nos concurrents. Cet outil ne fait qu’utiliser les données publiques disponibles sur leur site en toute légalité. Nous n’utilisons ces données qu’en interne, rien n’est publié. Enfin, il n’y a aucune protection anti-scraping sur notre site, alors enjoy ❤️
L’outil de veille que nous imaginions
Comme vous le savez sûrement, notre métier, c’est la formation professionnelle pour développeur·se·s. Même si nous avons parfois la chance d’être les seuls à donner une formation sur un sujet spécifique en France, la plupart du temps il y a d’autres concurrents sur le coup.
Par exemple, quand nous travaillons sur une nouvelle formation, il est intéressant de regarder ce que fait la concurrence pour nous positionner en terme de prix, de durée, de SEO… Jusqu’à maintenant nous le faisions à la main quand nous en avions besoin, mais c’était très incomplet. Impossible, par exemple, de connaître toutes les nouvelles formations d’un concurrent qui en a plusieurs dizaines voire centaines à son catalogue. Il était temps de revoir notre façon de faire !
Nous avons donc réfléchi à un outil permettant d’automatiser notre veille concurrentielle (et veille tarifaire). Nous avions en tête d’avoir les fonctionnalités suivantes :
- suivre les ajouts/suppressions de formations,
- suivre les modifications de certains attributs (prix, durée, titre, programme…),
- bonus : lister les formations qui marchent sûrement le mieux (en se basant sur le nombre de commentaires, notes…),
- bonus : lister les formations correspondant à un mot clé (en affichant des infos utiles comme le prix, la durée, …),
- bonus : retracer les évolutions de prix (ou autre attribut) d’une formation,
- bonus : avoir les statistiques générales sur nos concurrents (nombre de formations, prix moyen… ).
1er essai : Apify + cron Ruby + gist
Vous le savez, le pragmatisme est une règle d’or chez nous. Il y a 1 ou 2 ans, nous avions planché sur une première version de cet outil. (spoiler alert : on a vite arrêté de l‘utiliser car pas du tout user friendly)
Pour cette première itération nous avions choisi la solution technique suivante :
- scraper régulièrement les sites avec Apify,
- récupérer les données avec un cron de quelques lignes de Ruby hébergé sur Heroku,
- puis les exporter sous forme de CSV sur un gist privé.
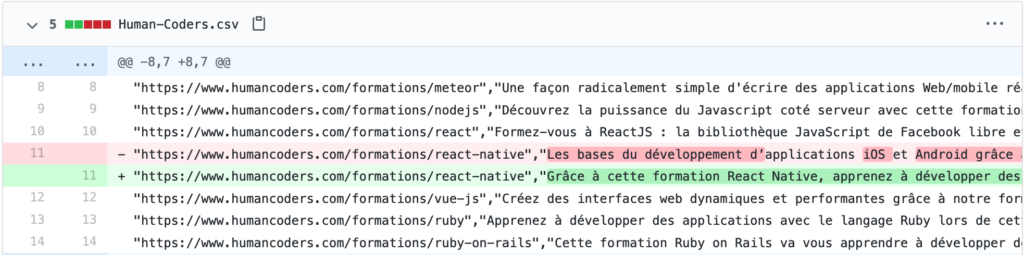
Comme vous pouvez le voir sur la capture, nous avions un fichier CSV par concurrent et chaque ligne correspondait à une formation. Comment nous triions toujours les formations dans le même ordre, nous obtenions un joli diff à chaque exécution du cron.
Nous avons vite trouvé laborieux de consulter ces fichiers de diff qui faisaient plusieurs milliers le ligne pour trouver des changements intéressants. Cette première de l’outil est vite tombé dans l’oubli 😓 (mais ça doit suffire si vous n’avez que quelques dizaines de produits à surveiller… ou de la patience 😃).
La bonne solution : Apify + Rails + Metabase
Nous avons profité du confinement pour revenir sur ce projet que nous avions mis de côté, car peu pratique. Entre temps, nous avons pris l’habitude d’utiliser Metabase pour faire des dashboards en interne ou simplement analyser et questionner nos données.
Pour cette 2ème itération de cet outil de veille concurrentielle, nous avons choisi de conserver Apify pour le scraping car cela marche bien. Les données scrapées sont ensuite envoyées à une appli Rails très simple et développée par nos soins. Cette appli s’occupe de récupérer les données d’Apify, de valider les données reçues et de les sauver (et versionner) en base.
Enfin, nous avons utilisé Metabase pour interroger cette base et visualiser les données. On vous explique tout ça en détail
Le scraping avec Apify
Côté Apify, c’est assez simple. Pour chaque site, il faut donner quelques règles pour le parcours du site (URL de départ, pattern des liens à suivre…). Ensuite, pour chaque page on retourne les infos que l’on souhaite garder sous forme de hash. Pour info, nous aurions très bien pu utiliser d’autres services de scraping en ligne, ou au contraire, utiliser des solutions à héberger soi-même comme Scrapy ou l’équivalent en Ruby, Kimurai.
Nous avons choisi d’utiliser un service en ligne pour pouvoir nous concentrer sur l’essentiel et ne pas risquer de perdre du temps en admin sys pour le moment. Il est facile de migrer sur une autre techno à tout moment car leur fonctionnement est généralement assez similaire.
Avec Apify, suivant l’acteur utilisé, la façon de récupérer les données sur la page peut varier. La plupart du temps, nous avons utilisé le Cheerio Scraper. Il est très rapide car il n’exécute pas le JavaScript. Le scraping se fait via Cheerio, une lib Node.js qui ressemble très fortement à jQuery à l’usage. Le scraping est suffisamment rapide pour que nous puissions parser plusieurs milliers de pages chaque semaine tout en restant dans les quotas de l’offre gratuite pour le moment.
Voici, par exemple, le code utilisé pour le scraping de Human Coders : https://gist.github.com/camilleroux/738f3efc2d42d4c54f380d01ae01ba37
Et voici le résultat que nous obtenons en JSON :

L’appli Rails
Nous avons codé une petite application Ruby on Rails : elle nous permet de récupérer les données dès qu’un webhook de Apify nous signale qu’un site a été parsé, ainsi que de stocker ces données en base.
Notre modèle de données comporte 3 tables :
- companies : id, name, apify_actor_id, …
- courses : id, ref (identifiant unique utilisé par la société, généralement l’URL ou la référence), url, price, … others (champs jsonb pour stocker toutes les autres infos qui n’ont pas de champs spécifiques)
- versions : item_type, item_id, event, object, object_changes, …
À chaque webhook, nous :
- récupérons l’entrée de companies correspondant au site qui vient d’être scrapé,
- téléchargeons le dernier dataset de la tâche Apify au format JSON,
- créons ou modifions chaque formation,
- supprimons les formations présentes en base mais qui ne sont plus dans le dataset.
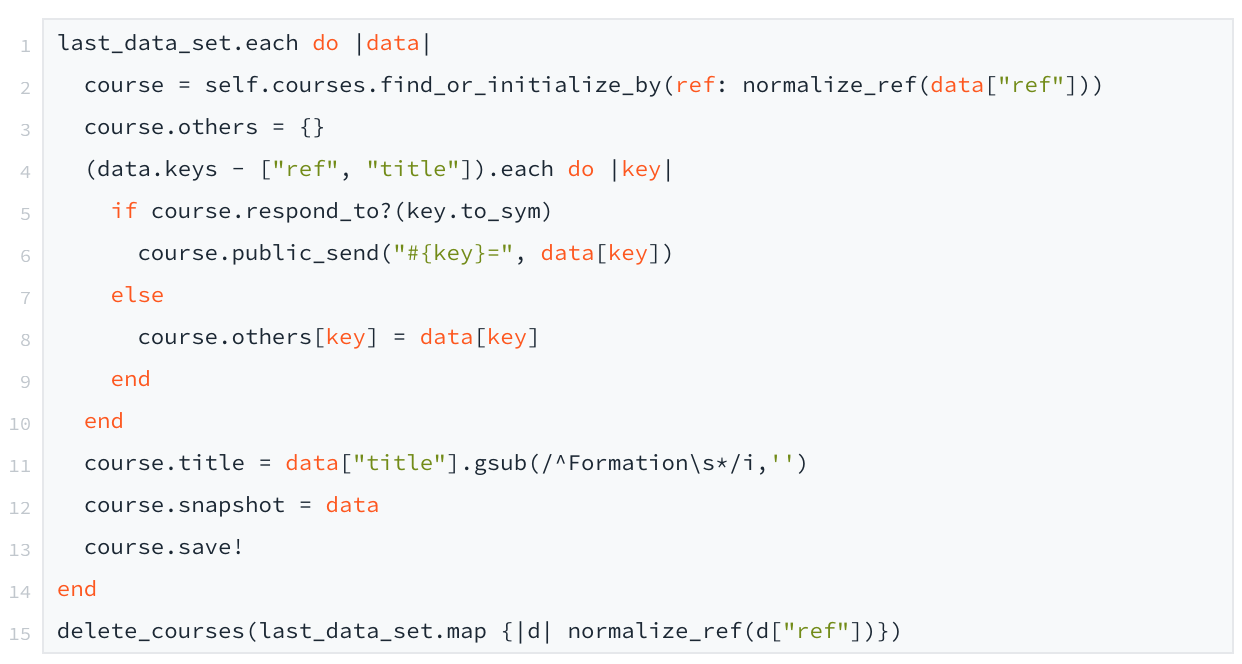
Voici le code qui s’occupe des deux derniers points :
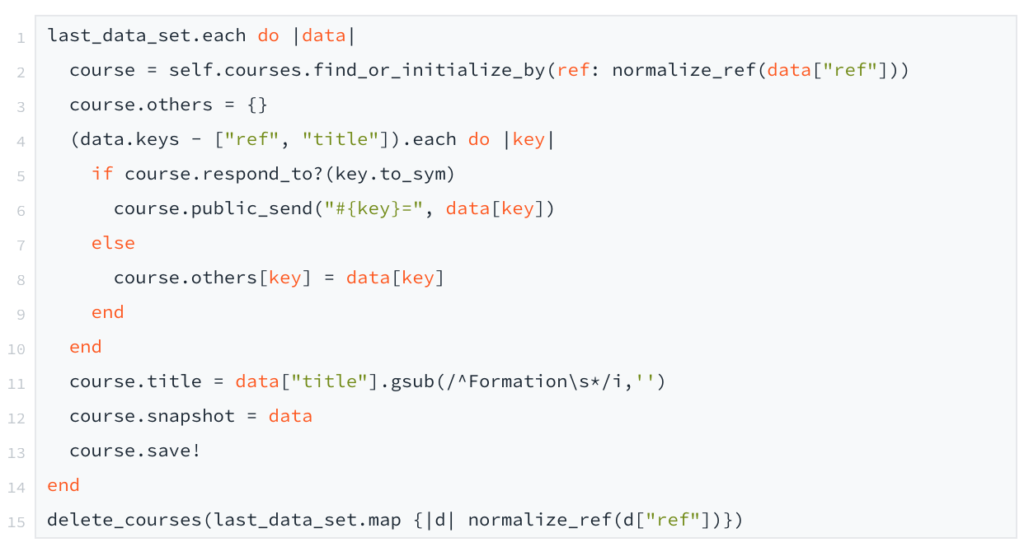
Comme vous pouvez le voir, pour chaque attribut du JSON, nous l’affectons à l’attribut de courses s’il existe, sinon nous l’ajoutons au dictionnaire others. Nous aurions aimé avoir un modèle courses plus générique. Mais l’éditeur de Metabase ne gérant pas le jsonb pour le moment, nous avons préféré avoir des champs spécifiques pour la plupart des données que nous pensions rechercher/filtrer/trier…
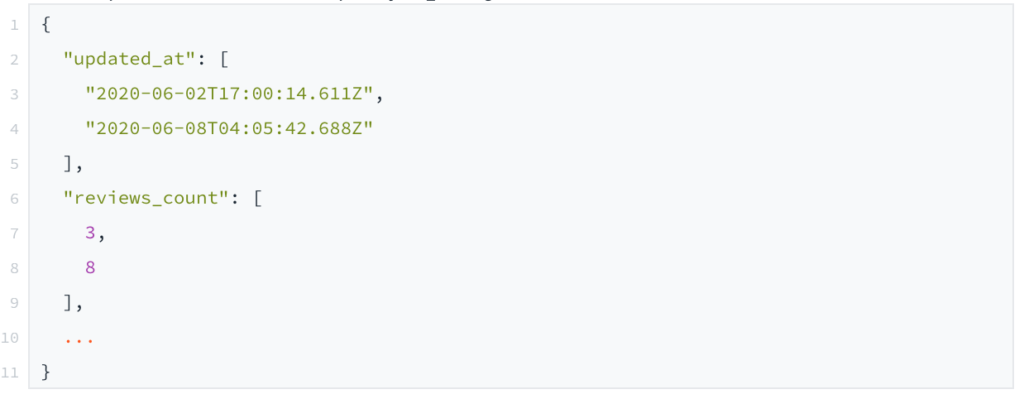
Pour conserver l’historique, nous avons utilisé la gem paper_trail. Avec une seule ligne de code, elle gère tout le versionning de courses. Il nous a suffit d’ajouter has_paper_trail au modèle Course, pour qu’à chaque sauvegarde il crée une Version avec :
- les changements qui ont eu lieu (object_changes),
- l’objet tel qu’il était avant (object)
- le type d’événement (event) : create, update, destroy
Voici à quoi ressemble le champs object_changes de versions :
Maintenant que nous avons plein de données en base, il est temps de les exploiter. C’est là que Metabase entre en jeu !
Metabase
Metabase est un outil qu’on aime beaucoup chez Human Coders. On s’en sert souvent pour faire des tableaux de bord pour l’équipe, avoir des stats sur tout et n’importe quoi.Metabase peut se connecter à plein de bases de données différentes. Nous l’avons donc connecté à la base PostgreSQL du projet Heroku et nous avons commencé à jouer avec les données sauvées par notre appli Rails.L’interface est très ergonomique. La plupart des infos ont pu être affichées sans la moindre ligne de SQL 😎
Voici quelques exemples de dashboards que nous avons pu faire :
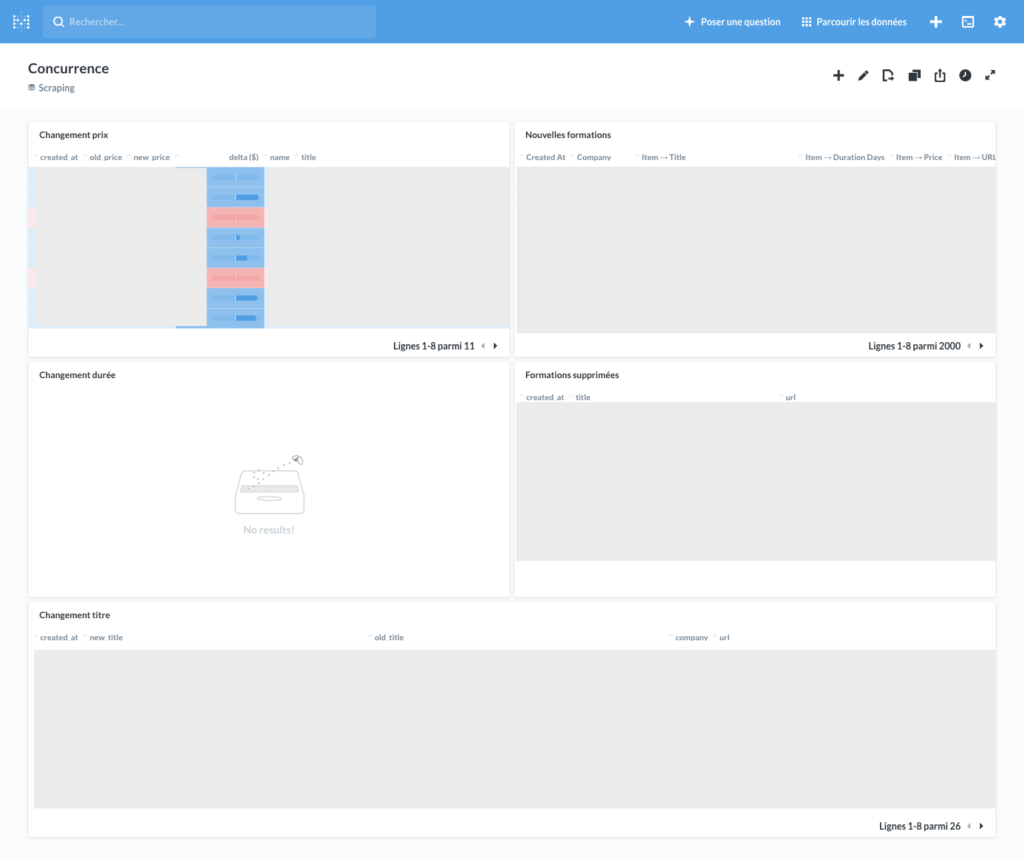
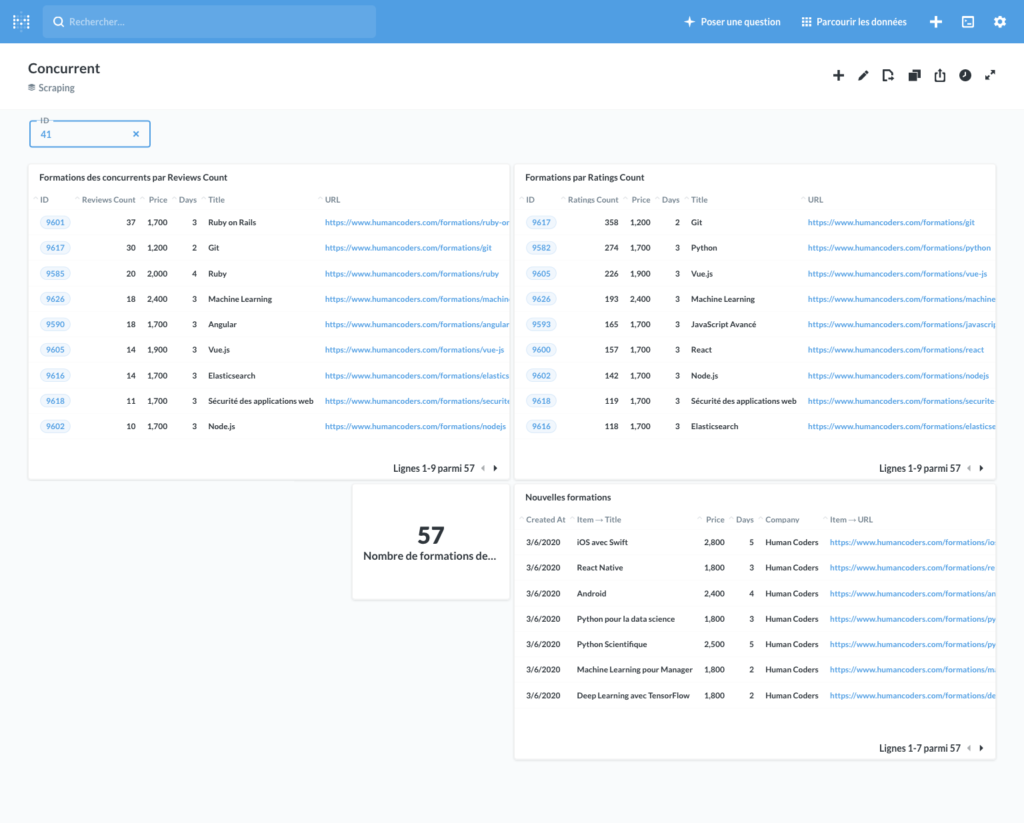
Voici maintenant quelques exemples de requêtes que nous avons utilisées pour ces tableaux de bord.
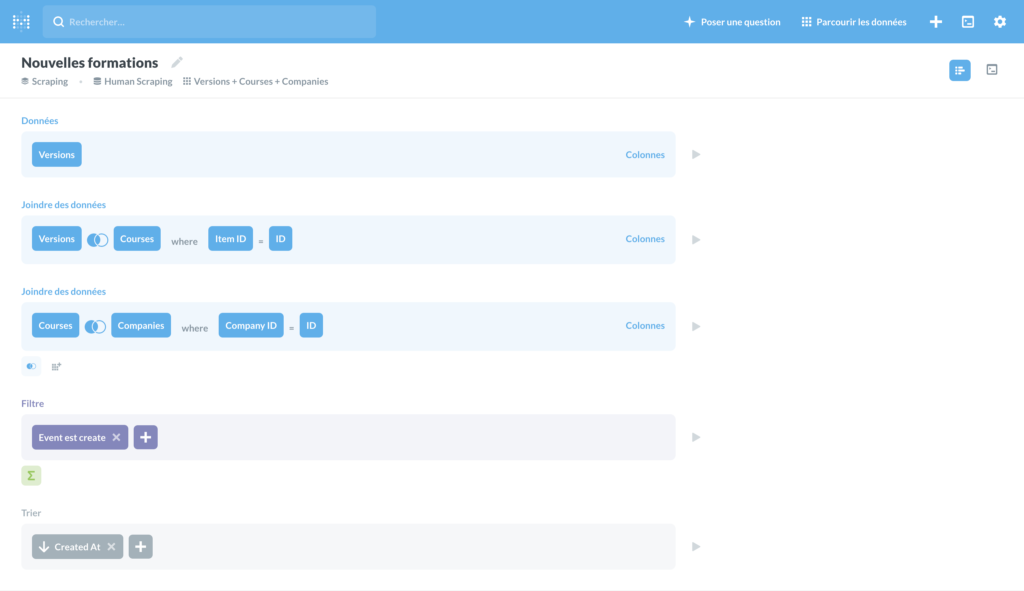
Lister les nouvelles formations
Il suffit de récupérer toutes les versions dont l’event est “created”, de faire une jointure avec courses et companies pour avoir toutes les infos… et de trier par created_at. Le tour est joué !
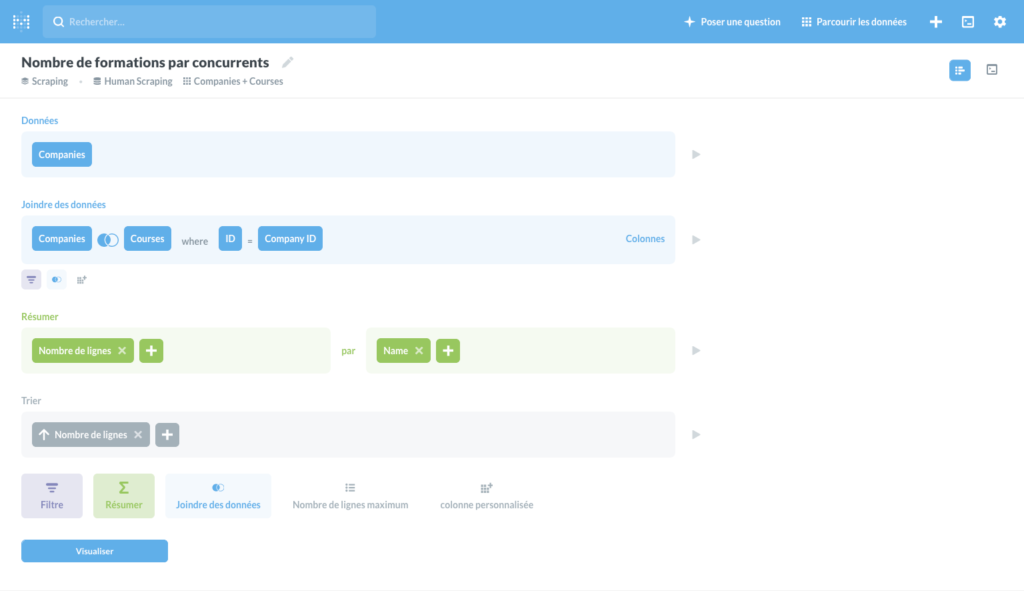
Afficher le nombre de formations par concurrent
Une jointure, un group by sur le nom de la company…
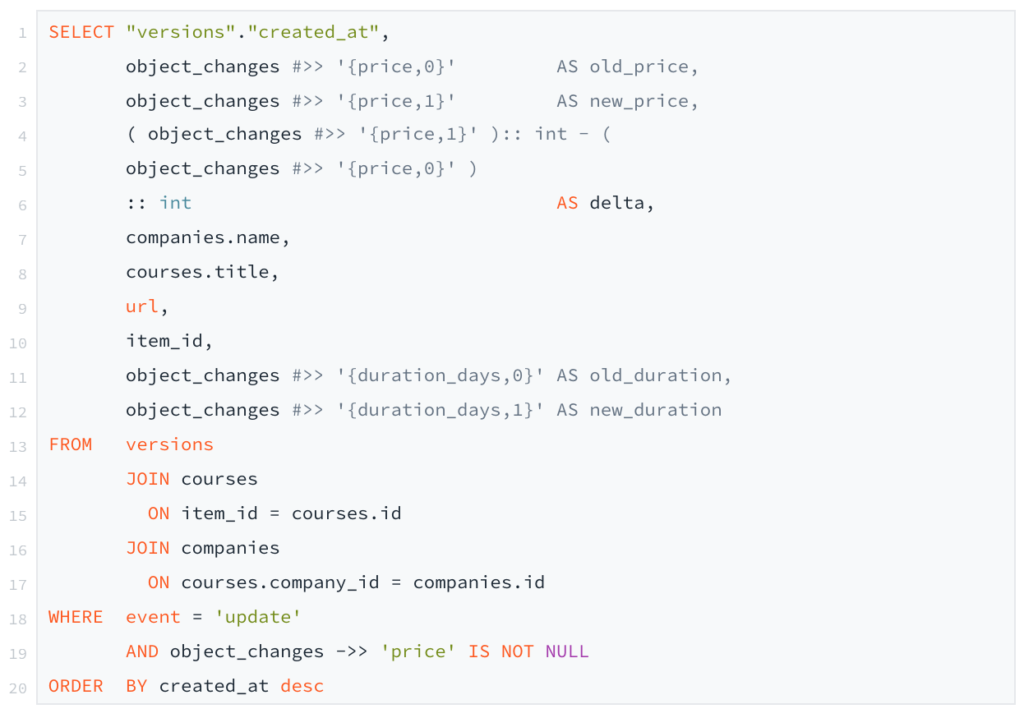
Lister les changements de prix chez nos concurrents
Pour lister tous les changements de prix nous avons dû faire une requête SQL à la main car l’éditeur de Metabase ne sait pas encore gérer le jsonb.
Là aussi rien de très compliqué au final. Il suffit de récupérer les versions dont event = `update`et dont le champ object_changes contient une clé “price”. Un jointure avec courses et companies, ainsi qu’un tri par created_at et… voilà !
Une 3ème itération ?
Pour le moment on attend de voir ce que ça donne à l’usage. L’outil tel qu’il est en ce moment nous aide déjà beaucoup.
Quand nous aurons plus de données, nous pourrons obtenir de nouvelles infos intéressantes :
- l’évolution du prix (ou n’importe quel autre attribut) d’une formation donnée dans le temps,
- l’évolution du nombre de formations au catalogue d’un concurrent,
- la liste des formations qui ont eu le plus de nouveaux commentaires/notes ces derniers mois,
- …
Nous réfléchissons aussi à coder une vue dans notre appli Rails pour afficher le diff entre deux versions d’une formation, pour notamment mieux visualiser les changements de programmes.
Nous avons pensé à open sourcer le code, mais ce n’est pas très pratique car une bonne partie de ce qui est intéressant est sur Apify ou Metabase, et le modèle de données de notre appli est très spécifique à notre métier pour le moment.
Nous avons essayé de vous mettre un maximum d’info dans l’article, mais si vous avez des questions ou suggestions, on peut en parler dans les commentaires.
J’espère que nous vous avons donné des idées 😀 Amusez-vous bien !