
How we monitor competitor's prices with Apify and Metabase


Today we're going to talk about automated analysis of competition. We have developed a tool to stay up to date with developments in the product catalog (in this case, the training) of our competitors. The method used is not specific to our market and as we had fun coding all of this, we decided to share it with the world :)
Disclaimer: We are always very respectful of our competitors. This tool only uses the public data available on their site, legally. We only use this data internally, and nothing is published. Finally, there is no anti-scraping protection on our site, so enjoy ❤️
Re-imagining monitoring tools
As you probably know, our job is professional training for developers. Even if we are sometimes lucky enough to be the only ones providing training on specific topics in France, most of the time, there are competitors.
For example, when we are working on a new training, it is interesting to look at what the competition is doing to position ourselves in terms of price, duration, SEO… Until now, we did it by hand when needed, but it was fairly incomplete. For example, it’s impossible to find out about all the new training courses for a competitor who provides several dozens or even hundreds of trainings in their catalog.
It was time to think outside the box! So we thought about a tool to automate our tracking of our competitors (and price intelligence). We had in mind to have the following features:
- follow new additions / deletions of training,
- follow the modifications of certain attributes (price, duration, title, program, etc.),
- bonus: list the courses that probably work best (based on the number of comments, ratings, etc.),
- bonus: list the training courses corresponding to a keyword (by displaying useful information such as price, duration, etc.),
- bonus: trace the price changes (or other attribute) of a training,
- bonus: have general statistics on our competitors (number of training courses, average price, etc.).
1st try: Apify + cron Ruby + gist
As you know, we highly value pragramatism. 1 or 2 years ago, we were working on a first version of this tool (spoiler alert: we quickly stopped using it because it was not user friendly at all).
For this first iteration we chose the following technical solution:
- regularly scrape sites with Apify,
- retrieve the data with a cron job of a few lines of Ruby hosted on Heroku,
- then export them as CSV to a private gist.
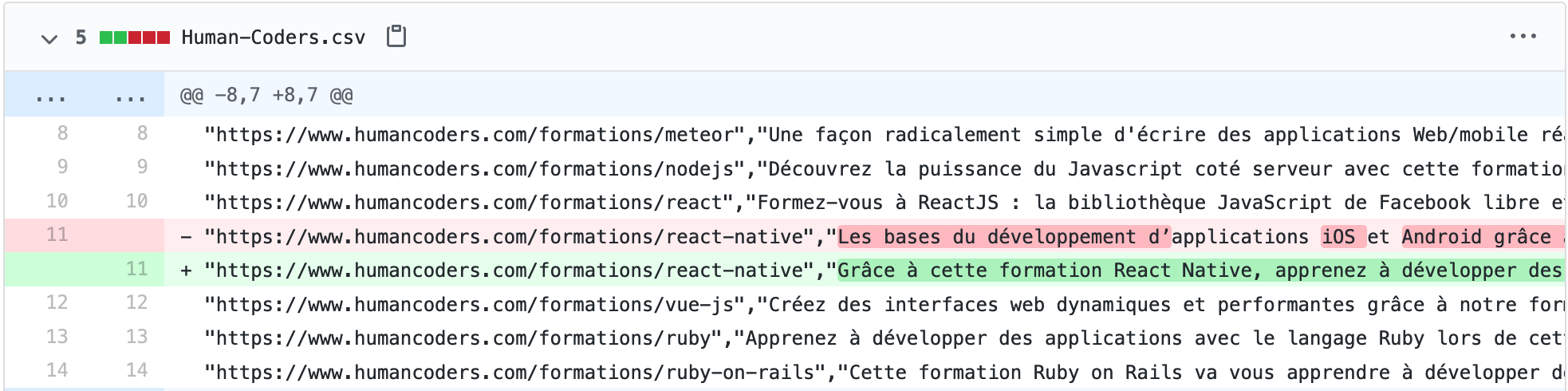
As you can see in the screenshot, we had one CSV file per competitor and each line was associated with a course. As we always sort the course in the same order, we get a nice diff with each execution of the cron job. It was quickly difficult to identify interesting changes by consult these diff files which had thousands upon thousands of lines.
This first iteration of the tool quickly fell out of favor 😓 (but it should be enough if you only have a few dozen products to watch ... or patience 😃).
The right solution: Apify + Rails + Metabase
We took advantage of the quarantine to come back to this project that we had put aside because it was impractical. In the meantime, we've gotten into the habit of using Metabase to do internal dashboards or to simply analyze and query our data.
For the 2nd iteration of this competition monitoring tool, we have chosen to keep Apify for scraping because it works well. The scraped data is then sent to a very simple Rails app developed by us. This app retrieves data from Apify, validating the data received and saving it (and versioning) in the database.
Finally, we used Metabase to query this database and visualize the data. We explain all this in detail.
Scraping with Apify
The Apify side of things is pretty simple. For each site, we need to provide some rules for the traversal of the site (starting URL, pattern of the links to follow, etc.). Then, for each page, we return the information that we want to keep as a hash. FYI, we could very well have used other online scraping services, or go with self-hosting solutions like Scrapy or its Ruby equivalent, Kimurai.
We've chosen to use an online service so that we can focus on the essentials and not risk wasting time on sysadmin tasks. It is easy to migrate to another technology at any time because their workflow is generally quite similar.
With Apify, depending on the actor used, the way to retrieve the data on the page can vary. Most of the time, we used the Cheerio Scraper. It is very fast because it does not execute JavaScript. Scraping is done via Cheerio, a Node.js library that very resembles jQuery in its usage. The scraping is fast enough that we can parse several thousand pages each week while keeping the resources within the bounds of the free account for the moment.
Here, for example, is the code used for Human Coders scraping: https://gist.github.com/camilleroux/738f3efc2d42d4c54f380d01ae01ba37
And here is the result we get in JSON:

The Rails app
We wrote a small Ruby on Rails application: it allows us to retrieve data as soon as a webhook from Apify informs us that a certain site was successfully parsed. It also stores this data in the database.
Our data model is made of 3 tables:
- companies: id, name, apify_actor_id, etc.
- courses: id, ref (unique identifier used by the company, usually the URL or reference), url, price, etc. (jsonb fields to store all other information that does not have specific fields)
- versions: item_type, item_id, event, object, object_changes, etc.
At each webhook, we:
- recover the entry for the companies corresponding to the site which has just been scraped,
- download the last dataset of the Apify task in JSON format,
- create or modify each training,
- remove the course present in the database but is no longer in the dataset.
Here is the code that takes care of the last two points:
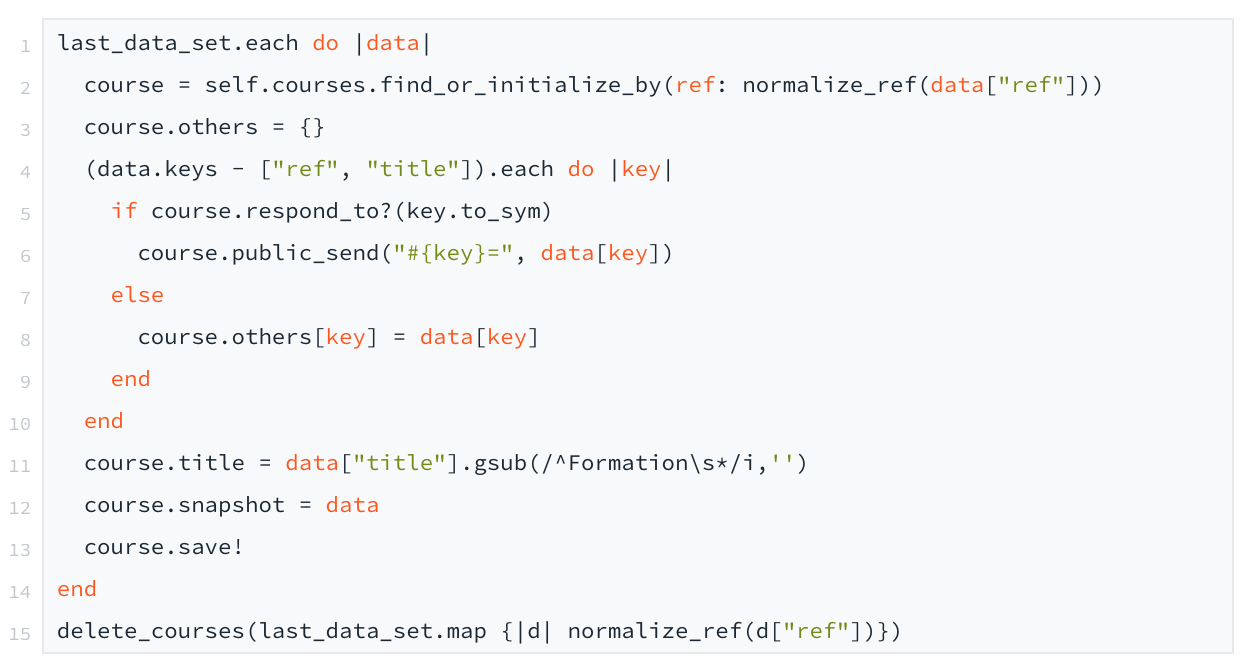
As you can see, for each attribute of the JSON, we assign it to the courses attribute if it exists. Otherwise, we add it as "others" in the dictionary. We would have liked to have a more generic model for courses. But the Metabase editor does not manage jsonb at the moment, and we have chosen to have specific fields for most of the data that we thought to search/filter/sort/etc.
To keep track of the history, we used the gem paper_trail. With a single line of code, it manages versioning of courses. All we have to do is add has_paper_trail to the Course model, so that on each save it creates a Version with:
- the changes that have taken place (object_changes),
- the object as it was before (object)
- the type of event (event): create, update, destroy
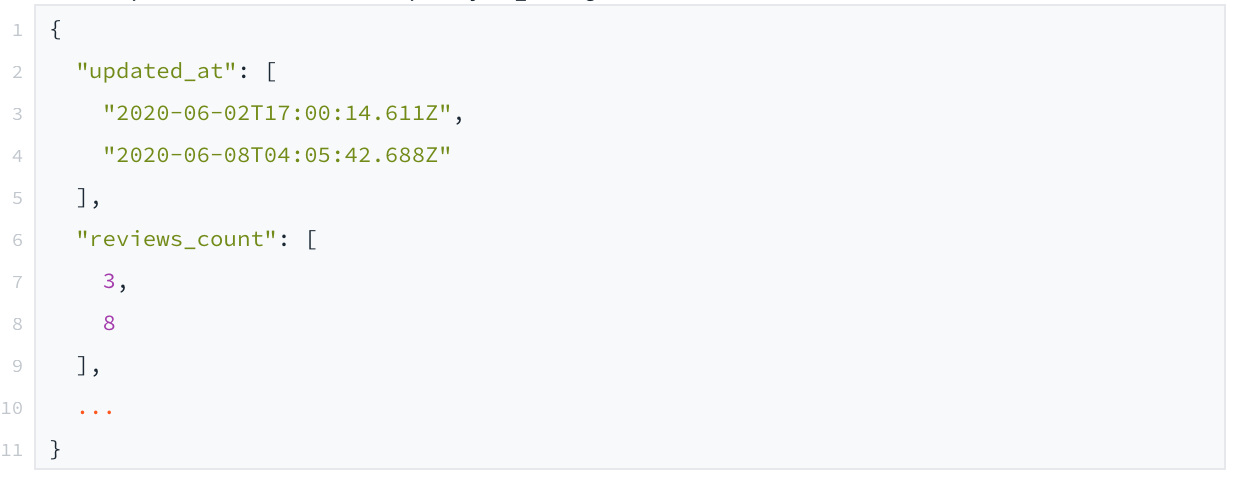
Here is what the object_changes version field looks like:
Now that we have a lot of data in the database, it's time to put it to good use. This is where Metabase comes in!
Metabase
Metabase is a tool we really like at Human Coders. It is often used to make dashboards for the team, to have stats on everything and anything. Metabase is able to connect to lots of different databases. So we connected it to the PostgreSQL database of the Heroku project and we started playing with the data saved by our Rails app. The interface is very ergonomic. We were able to display most of the info without a single line of SQL 😎
Here are some examples of dashboards we were able to make:
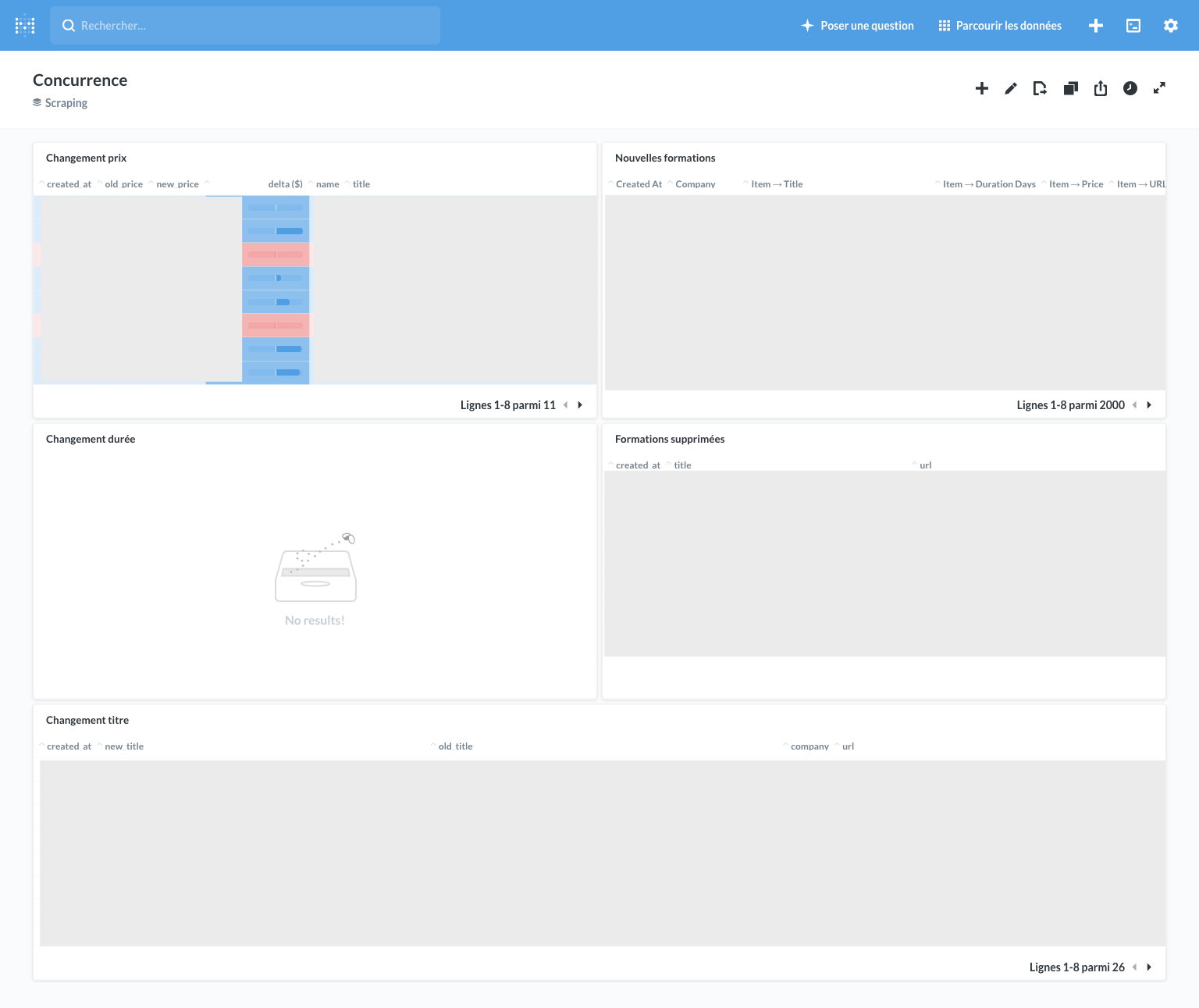
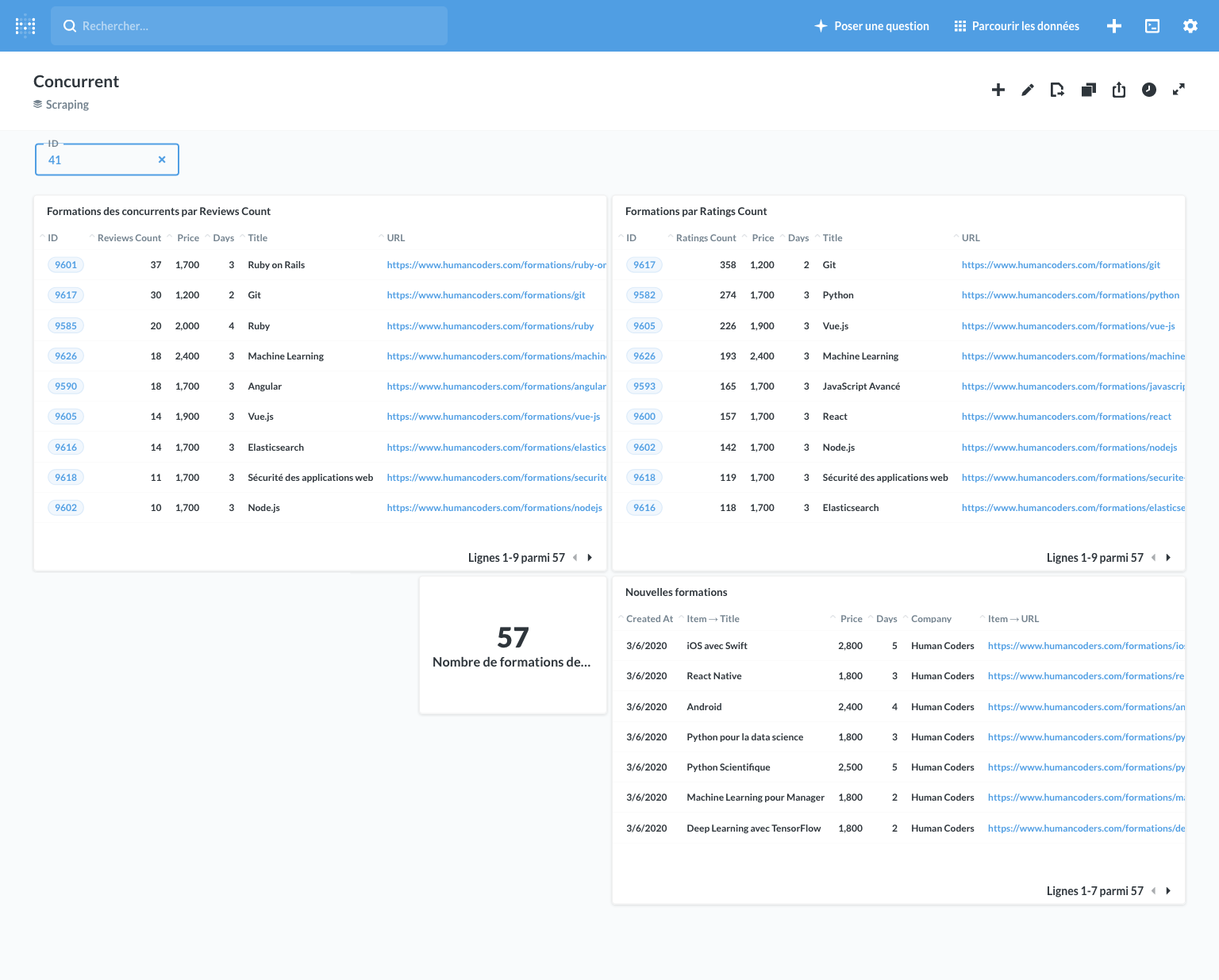
Here are some examples of the queries we used for these dashboards.
List new courses
You just have to get all the versions whose event is “created”, make a join with courses and companies to have all the info, and sort by created_at. And that's that!
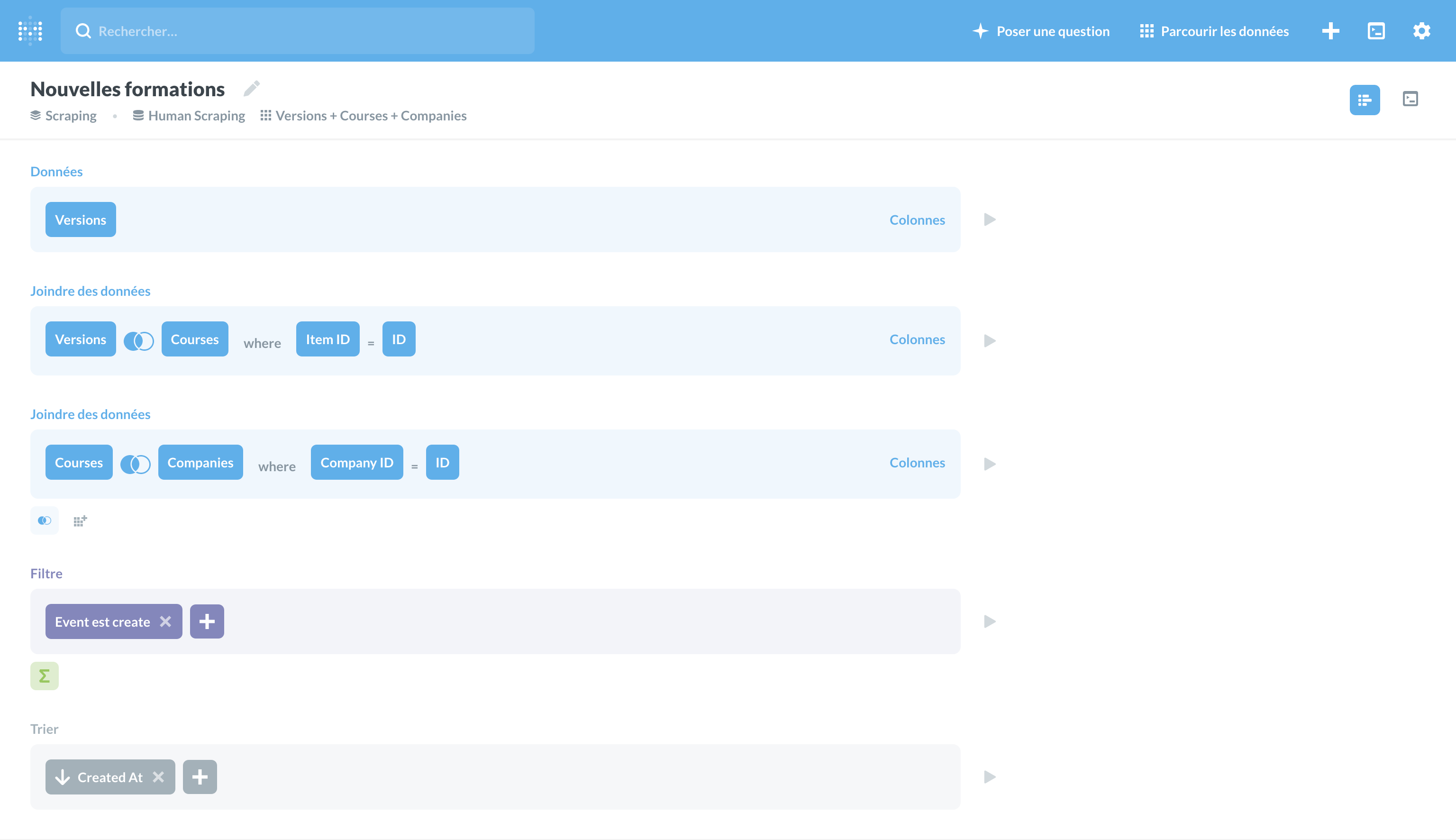
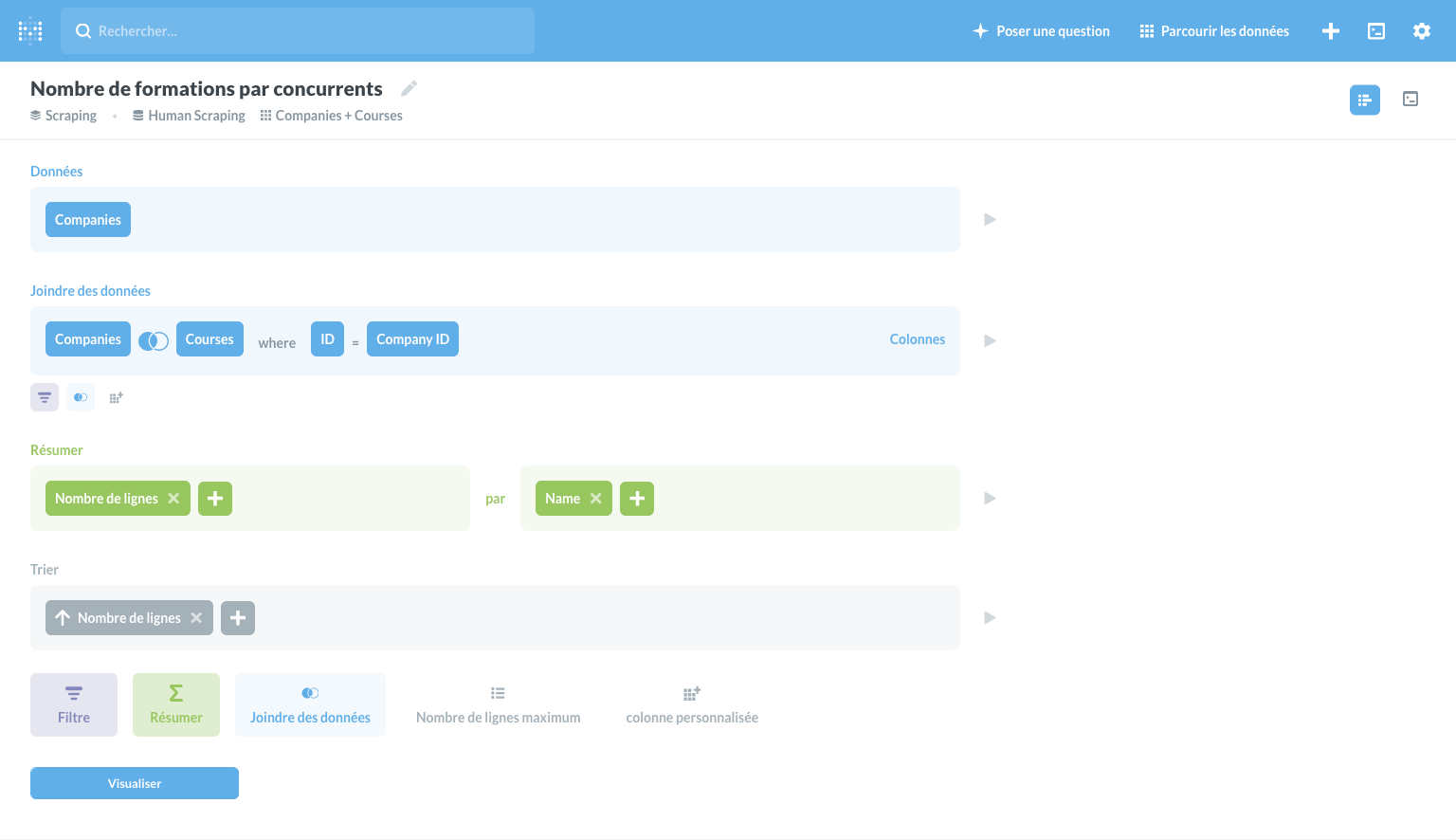
Display the number of training courses per competitor
A join, a group by, on the company's name and...
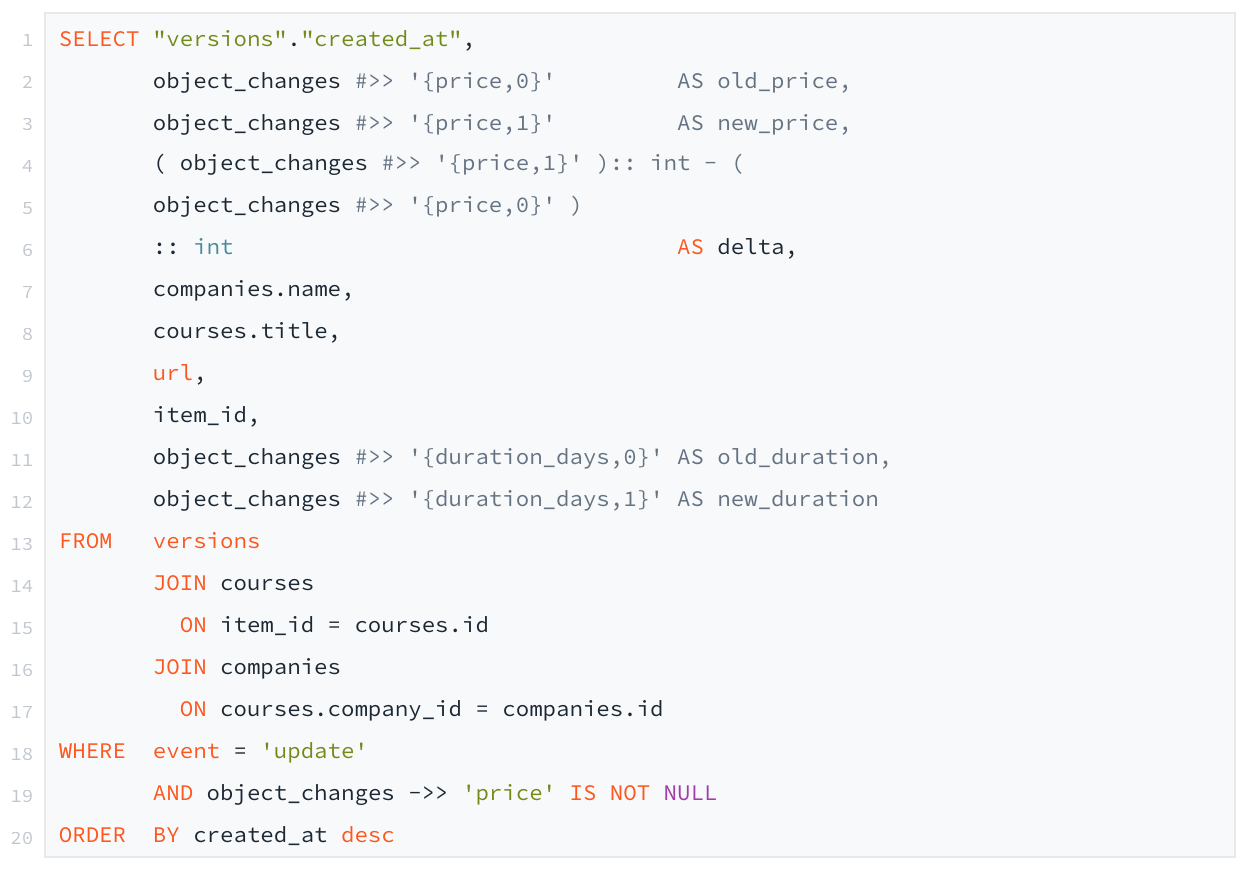
List price changes from our competitors
To list all the price changes we had to do an SQL query by hand because the Metabase editor does not yet know how to manage jsonb. At the end of the day, none of this was complicated either. You just have to get the versions where event = `update` and where object_changes field contains a “price” identifier. A join with courses and companies, as well as a sort by created_at and...voila!
A third iteration?
For the moment, we are waiting to see how this will perform in daily usage. The tool as it stands right now is very helpful.
When we have more data, we can get some interesting new info such as:
- the evolution of the price (or any other attribute) of a given training over time,
- the evolution of the number of training courses in a competitor's catalog, the list of courses that have had the most new comments/ratings in recent months,
- and more...
We are also thinking about coding a view in our Rails app to display the difference between two versions of a course. In particular, to better visualize program changes.
We thought about open-sourcing the code, but it's not very practical because a lot of what's interesting is on Apify or Metabase, and the data model of our app is very specific to our business at the moment.
We tried to put as much information as possible in the article, but if you have any questions or suggestions, we can talk about them in the comments. I hope we gave you some nice ideas 😀 Have fun!